Vector Embedding
Vector embeddings are essential in the world of artificial intelligence and data processing, as they help manage large datasets more effectively. This technique converts complex data into numerical vectors, making it easier to process, analyze, and utilize. Vector embeddings are particularly important in natural language processing (NLP), image recognition, and recommendation systems, where maintaining the context and meaning of the data is crucial.
What is Vector Embedding?
Vector embedding is a technique used to transform data into numerical vectors that capture the relationships and meanings within the data. This method organizes data in a way that facilitates easier processing and analysis. In the context of text processing, vector embeddings ensure that each text segment is converted into a vector, retaining the original context and meaning for efficient handling by AI models.
Why a Vector Embedding Strategy is Essential
1. Enhanced Processing Efficiency
Large datasets can be tough for AI models. Vector embeddings break data into smaller, manageable vectors, making processing faster and more efficient. This approach optimizes computational resources, reducing processing time and costs.
Example: Processing an entire book at once isn’t practical. By converting the book into vector embeddings for chapters or paragraphs, AI handles the text more efficiently.
2. Improved Model Performance
AI models work better with smaller, contextually relevant data chunks. Large, unprocessed datasets can overwhelm models, causing errors and reducing accuracy. Vector embeddings ensure manageable, contextually appropriate data, enhancing performance.
Example: Sentiment analysis models perform better when analyzing sentences or paragraphs rather than entire documents.
3. Maintaining Context and Coherence
AI models need data that retains its original context and coherence to produce meaningful outputs. Poorly managed data can lose context, leading to irrelevant or incorrect results. Vector embeddings help preserve data context and meaning.
Example: In a chatbot, breaking down user queries into coherent vector embeddings ensures accurate responses.
3. Facilitating Retrieval and Answering Systems
Effective vector embedding is key for systems that retrieve information based on user queries. Accurate embeddings ensure relevant data retrieval, enhancing system reliability and user satisfaction.
Example: In a document retrieval system, breaking documents into well-defined vector embeddings allows quick identification of relevant information.
4. Supporting Diverse Data Formats
Different data types—like text, images, and audio—require tailored embedding strategies. A robust vector embedding strategy handles various formats effectively, ensuring correct data processing regardless of structure.
Example: In a data processing pipeline with multiple document types, adaptive embedding strategies ensure appropriate handling based on content and format.
Different Types of Embedding Models
1. Word Embeddings
Word embeddings convert individual words into numerical vectors that capture semantic meanings and relationships. These models are fundamental in natural language processing tasks.
Need to discuss whether is there a need to show different types of embedding models and whether should we add some models as an example or their descriptions
Word2Vec
- Overview: Developed by Google, Word2Vec uses neural networks to learn word associations.
- Key Features:
- CBOW (Continuous Bag of Words): Predicts a target word based on context words.
- Skip-gram: Predicts context words based on a target word.
- Use Cases: Text classification, sentiment analysis, and similarity detection.
GloVe (Global Vectors for Word Representation)
- Overview: Developed by Stanford, GloVe captures global statistical information from a corpus.
- Key Features:
- Combines the benefits of matrix factorization and local context window methods.
- Use Cases: Document similarity, semantic analysis, and word analogy tasks.
FastText
- Overview: Created by Facebook, FastText extends Word2Vec by considering subword information.
- Key Features:
- Better handles rare words and morphologically rich languages.
- Use Cases: Language modeling, text classification, and named entity recognition.
2. Sentence Embeddings
Sentence embeddings represent entire sentences as vectors, capturing the meaning and context of the sentence as a whole.
BERT (Bidirectional Encoder Representations from Transformers)
- Overview: Developed by Google, BERT provides deep contextual embeddings by considering the entire sentence context.
- Key Features:
- Bidirectional: Looks at context from both directions (left and right).
- Transformer-based: Utilizes attention mechanisms for more accurate representations.
- Use Cases: Question answering, language inference, and text classification.
RoBERTa (Robustly Optimized BERT Pretraining Approach)
- Overview: An enhanced version of BERT with improved training techniques and performance.
- Key Features:
- Trained with more data and longer sequences.
- Removes the next sentence prediction objective.
- Use Cases: Similar to BERT, but with higher accuracy and robustness.
3. Document Embeddings
Document embeddings extend the concept to entire documents, allowing for the analysis of larger text blocks while preserving the context.
Doc2Vec
- Overview: An extension of Word2Vec that generates vectors for entire documents.
- Key Features:
- Paragraph Vector-Distributed Memory (PV-DM): Considers the document context along with the words.
- Paragraph Vector-Distributed Bag of Words (PV-DBOW): Ignores word order, focusing on predicting words randomly.
- Use Cases: Document classification, topic modeling, and information retrieval.
4. Contextual Embeddings
Contextual embeddings capture the meaning of words or phrases based on their usage in a particular context, which can change depending on surrounding text.
ELMo (Embeddings from Language Models)
- Overview: Developed by Allen Institute for AI, ELMo provides deep contextualized word representations.
- Key Features:
- Utilizes bidirectional LSTM (Long Short-Term Memory) networks.
- Generates embeddings that change with context.
- Use Cases: Named entity recognition, sentiment analysis, and coreference resolution.
GPT (Generative Pre-trained Transformer)
- Overview: Developed by OpenAI, GPT models use a transformer architecture to generate text-based on input prompts.
- Key Features:
- Unidirectional: Processes text in a left-to-right manner.
- Pre-trained on vast text corpora and fine-tuned for specific tasks.
- Use Cases: Text generation, summarization, and conversational AI.
5. Multimodal Embeddings
Multimodal embeddings integrate data from different modalities, such as text, images, and audio, into a unified vector space.
CLIP (Contrastive Language-Image Pretraining)
- Overview: Developed by OpenAI, CLIP learns visual concepts from natural language descriptions.
- Key Features:
- Trained on a variety of internet images with corresponding text.
- Can perform zero-shot classification.
- Use Cases: Image recognition, captioning, and cross-modal retrieval.
Understanding MTEB: Massive Text Embedding Benchmark
The Massive Text Embedding Benchmark (MTEB) is a comprehensive tool designed to evaluate the performance of various text embedding models across multiple natural language processing (NLP) tasks. By providing a standardized framework for comparison, MTEB helps researchers and developers select the best embedding models for their specific needs.
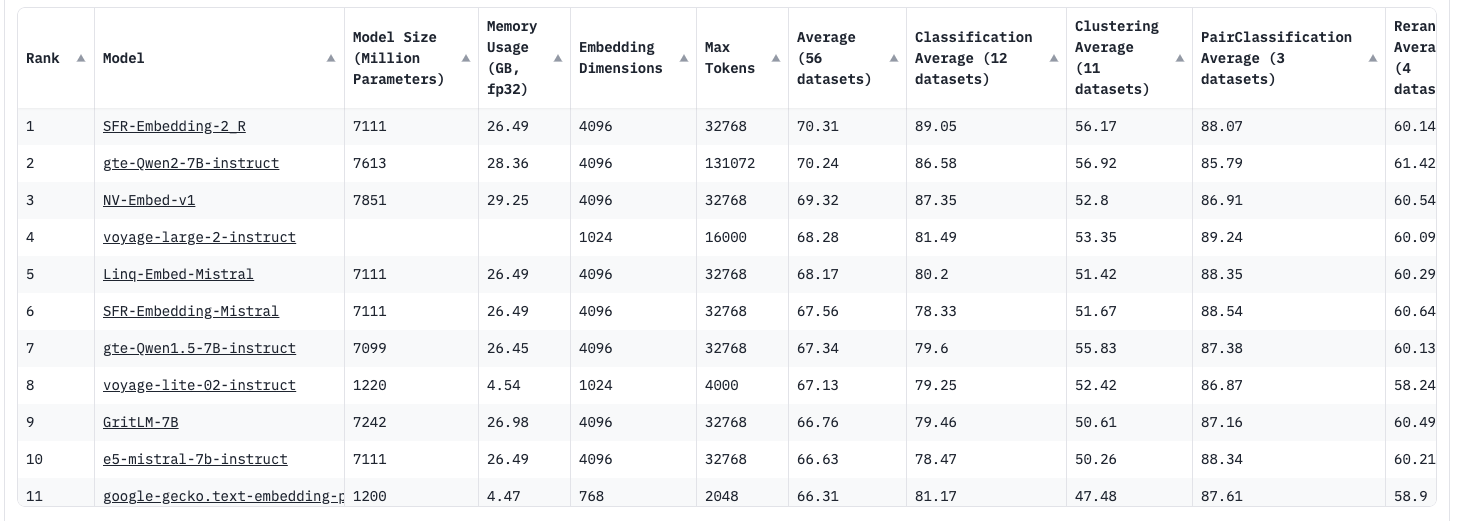
Why MTEB is Important?
Choosing the right text embedding model is critical for achieving optimal results in NLP applications. MTEB addresses this need by offering:
- Standardized Evaluation: MTEB provides a consistent set of benchmarks to assess different models, ensuring fair and reliable comparisons.
- Wide Coverage: It includes a variety of tasks, such as classification, clustering, and information retrieval, reflecting real-world use cases.
- Performance Insights: By using MTEB, users can gain detailed insights into the strengths and weaknesses of each model, aiding in informed decision-making.
Components of MTEB
MTEB is structured around several key components:
- Benchmark Datasets: MTEB includes a diverse set of datasets that cover various languages, domains, and text lengths. This diversity ensures that models are tested across a broad spectrum of scenarios.
- Evaluation Metrics: It employs multiple evaluation metrics to provide a comprehensive assessment of model performance. Common metrics include accuracy, precision, recall, F1 score, and computational efficiency.
- Task Categories: MTEB encompasses multiple NLP tasks to evaluate the versatility of embedding models:
- Text Classification: Assessing the model's ability to categorize text into predefined classes.
- Clustering: Evaluating how well the model groups similar texts together.
- Information Retrieval: Testing the model's efficiency in retrieving relevant information from large datasets.
- Semantic Textual Similarity: Measuring how accurately the model captures the similarity between text pairs.
- Text Generation: Gauging the model's capability to generate coherent and contextually relevant text.
How to Use MTEB
Using MTEB involves several steps:
- Model Selection: Choose the text embedding models you wish to evaluate.
- Dataset Preparation: Use the benchmark datasets provided by MTEB for a standardized evaluation.
- Evaluation: Run the selected models on the benchmark datasets and record their performance across various metrics.
- Comparison: Compare the performance results to identify the best-performing models for your specific use case.
Benefits of MTEB
- Objective Comparison: MTEB eliminates biases by providing a neutral platform for model evaluation.
- Efficiency: It saves time by offering ready-to-use benchmark datasets and evaluation scripts.
- Informed Decisions: By offering detailed performance insights, MTEB helps in making data-driven decisions when selecting embedding models.
How to Choose the Best Embedding Model for Your Use Case
Selecting the right embedding model for your specific use case is crucial for maximizing the performance and efficiency of your AI applications. Here's a detailed steps to help you determine the best embedding model for your needs.
1. Understand Your Data and Requirements
The first step in choosing an embedding model is to thoroughly understand the nature of your data and the specific requirements of your application.
- Type of Data: Identify whether your data consists of text, images, audio, or a combination. Different embedding models are optimized for different data types.
- Text Data: Common in NLP tasks such as sentiment analysis, text classification, and machine translation.
- Image Data: Used in image recognition, object detection, and similar tasks.
- Audio Data: Applicable in speech recognition and audio classification.
- Application Requirements: Determine the specific goals of your application, such as classification, clustering, retrieval, or generation.
- Classification: Assigning categories to data points (e.g., spam detection, sentiment analysis).
- Clustering: Grouping similar data points together (e.g., topic modeling).
- Retrieval: Finding relevant information from a large dataset (e.g., search engines).
- Generation: Creating new data points based on existing data (e.g., text generation).
2. Evaluate Popular Embedding Models
Consider the most commonly used embedding models and their strengths and weaknesses:
- Strengths: Identify the key advantages of each model, such as their ability to capture semantic relationships, efficiency, and performance on specific tasks.
- Weaknesses: Note the limitations, such as computational requirements, training complexity, and potential issues with generalizability.
3. Benchmarking and Comparison
Use benchmarking tools like MTEB (Massive Text Embedding Benchmark) to compare the performance of different embedding models on tasks relevant to your use case.
- Performance Metrics: Evaluate models based on metrics such as accuracy, precision, recall, F1 score, and computational efficiency.
- Task Suitability: Ensure the model performs well on tasks similar to your application, such as sentiment analysis, text classification, or information retrieval.
4. Practical Testing and Validation
Implement a few shortlisted models and test them on your specific dataset. Evaluate their performance based on:
- Accuracy: Measure how well the model captures the nuances of your data.
- Speed: Assess the training and inference times to ensure they meet your application’s requirements.
- Scalability: Determine if the model can handle the scale of your data.
5. Consider Computational Resources
The availability of computational resources plays a crucial role in selecting an embedding model:
- Resource Availability: Ensure you have the necessary computational power (CPUs, GPUs) to train and deploy the model.
- Cost: Consider the cost of using proprietary models and balance it against the performance benefits they offer.
6. Flexibility and Integration
Choose a model that integrates well with your existing systems and offers flexibility for future updates:
- API Support: Check if the model has robust API support for easy integration.
- Community and Documentation: Prefer models with active communities and comprehensive documentation to facilitate troubleshooting and optimization.
Conclusion
Choosing the best embedding model for your use case involves understanding your data and application requirements, evaluating popular models, using benchmarking tools, conducting practical tests, considering computational resources, and ensuring flexibility and integration. By carefully assessing these factors, you can select the most suitable embedding model to enhance the performance and efficiency of your AI applications.